By Paul McLellan
如今,各式各樣的 3D 封裝呈增長趨勢,但還未引起廣泛關注。在 2019 年夏季的 HOT CHIPS 上,大部分設計並未採用單個大裸晶 (Die),而是採用同一封裝中的多裸晶設計方法。
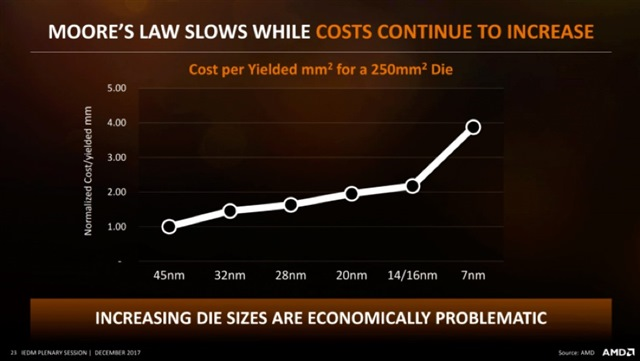
我們可以對「摩爾定律的終結」究竟意味著什麼展開探討,但是顯然,不再有令人信服的經濟理由將設計應用在 7 奈米 (及以下) 的工藝中。如果我們的需求是性能更高、或功率更低、或密度更低,那怎麼辦呢?直到最近,在設計中應用最尖端的工藝還能不僅實現上述需求,更能使每個電晶體的成本更低。也就是說,即使我們的設計是在前一代節點中執行的,也有經濟上的理由來保持領先。競爭環境也是推動因素 —— 如果我們不選擇轉移到先進節點,而競爭對手卻進行了轉移,那麼我們勢必會在成本耗費上處於巨大劣勢。在過去的幾年甚至幾十年中,制程節點的經驗法則表明:如果電晶體密度倍增,相比於之前的節點,每平方毫米的成本僅高出 15%;因此,成本節約了 35%。不過這種說法現在已不再成立,正如上方圖表所示,該圖表出自 Lisa Su 在 HOT CHIPS 上的主題演講。
另一個趨勢是 3D 封裝價格越來越低廉,因為不少設計都投入了大批量生產,其中尤以智慧手機和伺服器為多。正因成本平衡產生變化,如今,將所有專案整合到一個大型系統級晶片 (SoC) 上的方法不再像之前那樣吸引人;相比之下,將多裸晶整合到一個封裝更能引人矚目。儘管如何決策受設計的詳情和實際成本的影響,但未來趨勢方向是明確的 ——「超越摩爾」廣為人知,正逐漸取代「摩爾定律」的地位。
另一個製造現狀顯示,相比於分成獨立裸晶的相同設計,超大型晶片的良率更低。如果設計採用一個大型多核處理器或 FPGA,由於二者裸晶相同,故將設計分成多裸晶的方式更為可行。在所有設計的最高端領域,有一項硬性限制,即最大標線尺寸,也就是製造設備可以處理的最大設計。如果某項設計超過最大設計,則只能選擇將其分成多裸晶,除此之外,別無他法;也許,可以將其單獨封裝成「晶片組」,但更多採用的是 3D 封裝形式。
純數位之外的設計元件,例如類比、射頻、光子或高速 SerDes I/O 等,壓根無法從等比例縮小中得到任何好處。之所以將設計的此類元件在舊節點中保留,還有一個原因在於新節點早期上市時間,設計的此類元件需要測試晶片和矽工藝的驗證。如將其在舊節點中保留,這些測試晶片會脫離新節點中第一個設計的關鍵路徑。
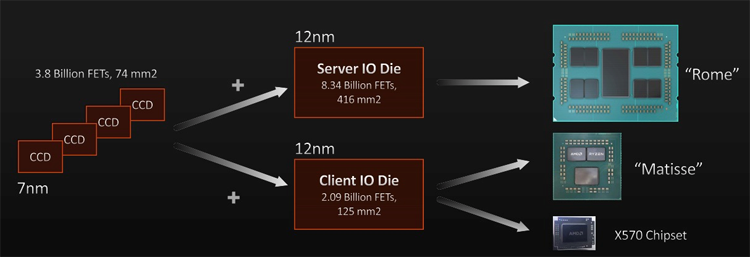
舉例說明:在 HOT CHIPS 上展示過的 AMD 的 Zen2。同一封裝中,AMD 的 Zen2 具有幾個相同的計算晶片和一個用戶端或伺服器 I/O 晶片。計算晶片內置 7 奈米,配備 3.8B 電晶體。伺服器和用戶端 I/O 晶片均內置 12 奈米。相比於配備 2B 電晶體的用戶端晶片,配備 8.3B 電晶體的伺服器晶片要大得多。在同一個仲介層上,AMD 的 Rome 伺服器產品配備八個計算晶片和伺服器 I/O 晶片。Matisse 用戶端版本配備兩個計算晶片和用戶端 I/O 晶片。查看上圖詳見展示。
HOT CHIPS 上展示的其他幾個設計方案也與之相似,即將純數位計算引擎設置進一個先進的節點,並在一個先進節點上製作第二個晶片來容納 SerDes、射頻、類比、光子等設計需要的專案。
Chiplets 小型裸晶
一旦人們接受並非所有專案都需要在同一個制程節點中進行設計這一觀點,則長遠來看,採用更模組化的 SoC 方案可能會更具吸引力,因為相對而言,會有較多小型裸晶,即 chiplets。
Chiplet 價值定位在於:
 |
靈活選擇元件的最佳制程節點。尤其是,SerDes I/O 和模擬無需設置在「核心」制程節點中。 |
|---|---|
|
裸晶尺寸小,良率更高 |
|
使用預先存在的 chiplets,縮短積體電路設計週期和整合複雜度 |
|
透過購買已知良好裸晶 (KGD),來降低製造成本 |
|
如在多個設計中使用同樣的 chiplets,則批量製造具有成本優勢 |
此法的長期願景是,系統級封裝 (SiP) 成為新的 SoC,而 chiplets 成為新的「IP」。然而,chiplets 之間需要配備標準 / 通用的通信介面,才能實現這一願景。
這個基本思路並非現在才被提出。事實上,戈登·摩爾 (Gordon Moore) 在其 1965 年的電子文章中就對後人熟知的摩爾定律進行了介紹,文中,他還表明:
「用較小的功能構建大型系統可能會更為經濟,這些功能是分開封裝和互連的。」
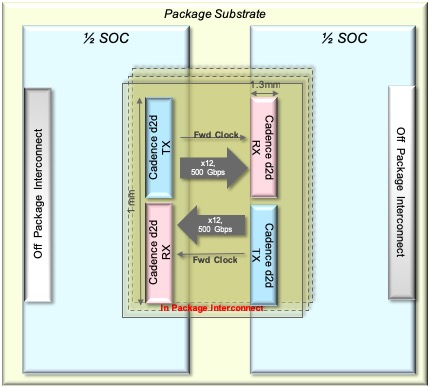
Die-to-Die (D2D,裸晶對裸晶) 互連
Cadence 公司已創建了一個 7 奈米 UltraLink D2D PHY IP 和一個測試晶片 (即測試 chiplet),包含用於晶片對晶片連接的 40G SerDes,以及裸晶對裸晶 (D2D) 的高頻寬、低功耗、低延遲封裝內互連。其功耗低、NRZ (與 PAM-4 相比),且不具有前向改錯碼 (FEC)。頂層設計的目標是將裸晶邊緣 (beachfront) 的頻寬提升至最大,避免 bump 間距過小,從而避免使用昂貴的矽基板 (不過,如有其他原因,例如使用 HBM 記憶體堆疊驅動,則可以使用這些矽基板)。
詳情如下:
|
線路速率為 20-40Gbps |
|---|---|
|
~500Gbps 雙向頻寬,1 毫米 beachfront |
|
@奈奎斯特 (25-40 毫米) 插入損耗為 8 db |
|
超低功耗 ~ 1.5pj/bit |
|
超低延遲 (~2.8ns TX,~2.6ns RX) |
|
直流耦合 |
|
前向時鐘原始比特誤碼率 1e-15,無前向改錯碼 |
|
單端 NRZ 信令,配備用於信號完整性和電源完整性的空間編碼 |
|
鏈路管理頻帶 |
|
MCM 應用的目標 bump 間距 (130u) |
|
支持矽仲介層的微型 bump |
40G PHY 眼圖如下所示:

範例設計
有關此技術支持的一種設計示例,詳見上圖所示的 25.6Tbps 交換機設計。其建立在有機基板上 (價格比仲介層更低);每個 chiplet 提供 1.2 Tbps 的頻寬,因此,其中 16 個 chiplets 的總頻寬為 25.6 Tbps。D2D 介面位於 chiplets 和交換機核心本身之間。

SEMI
與此同時,SEMI 發佈了 2019 年異構整合線路圖,概述和執行摘要可複製連結並訪問:http://suo.im/6igEtr

譯文授權轉載出處
長按識別 QRcode,關注「Cadence 楷登 PCB 及封裝資源中心」

歡迎關注 Graser 社群,即時掌握最新技術應用資訊


